|
Remco Royen I work as an Applied Scientist II at Amazon RIVR, where I sit at the intersection of modern AI and robotics. My mission is to build intelligent systems that translate complex visual data into real-world robotic action, scaling robust autonomous navigation to redefine last-mile delivery. Backed by a PhD and Postdoctoral tenure in Computer Vision at Vrije Universiteit Brussel (FWO fellowship), I specialized in 3D scene understanding, novel view synthesis, and scalable deep learning. I turned theoretical algorithms into patented, real-world solutions alongside industry partners like Xenomatix and VoxelSensors. Today, my core expertise spans embodied AI, Vision-Language Models (VLMs), and Vision-Language-Action (VLA) models, bridging the gap between perception and robust, autonomous decision-making in the physical world. Email / CV / LinkedIn / Google Scholar / GitHub |

|
News |
|
[03/2026] Following RIVR's acquisition by Amazon, I joined Amazon RIVR as an Applied Scientist II.
[02/2026] Promoted to Senior AI Engineer at RIVR. [07/2025] RT-GS2 was awarded the Best Poster Award at BMVA Computer Vision Summer School. [03/2025] I have joined RIVR in Zürich, Switzerland. [09/2024] My PhD thesis has been selected for presentation at BMVC 2024 Doctoral Consortium. [07/2024] Our paper, RT-GS2, has been accepted for presentation at BMVC 2024. [06/2024] I have succesfully defended my PhD thesis. |
Experience |
|
|
Amazon Applied Scientist II 2026-now |
|
|
RIVR (Acquired by Amazon in 2026) Senior AI Scientist - Computer Vision 2025-now |
|
|
Vrije Universiteit Brussel Postdoctoral Computer Vision Researcher 2024-2025 |
Education |
|
|
Vrije Universiteit Brussel PhD in Engineering Sciences (awarded summa cum laude) 2019-2024 |
|
|
Vrije Universiteit Brussel Master in Electrical Engineering (awarded summa cum laude) 2017-2019 |
|
|
Université libre de Bruxelles Master in Electrical Engineering (awarded summa cum laude) 2017-2019 |
|
|
Sapienza Università di Roma Master in Artificial Intelligence and Robotics (Exchange program) 2018-2019 |
Publications*Indicates Equal Contribution |

|
RT-GS2: Real-Time Generalizable Semantic Segmentation for 3D Gaussian Representations of Radiance Fields
Mihnea-Bogdan Jurca*, Remco Royen*, Ion Giosan, Adrian Munteanu British Machine Vision Conference (BMVC), 2024 [ArXiv] [Code] [Project Page] The first generalizable semantic segmentation method employing Gaussian Splatting. Our method is not only superior in segmentation quality, but also achieves real-time performance of 27 FPS, marking an astonishing 901 times speedup compared to the SOTA. |
 
|
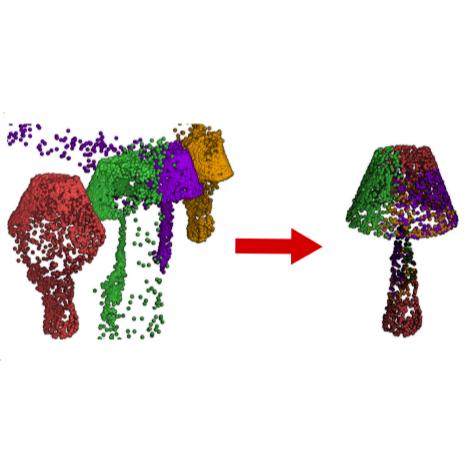
ProtoSeg: A Prototype-Based Point Cloud Instance Segmentation Method
Remco Royen, Leon Denis, Adrian Munteanu Signal Processing: Image Communication, 2026 [ArXiv] [Paper] [Code] A 3D instance segmentation method which simultaneously learns coefficients and prototypes. The obtained prototypes are visualizable and interpretable. Experiments on S3DIS-blocks and PartNet. |
|
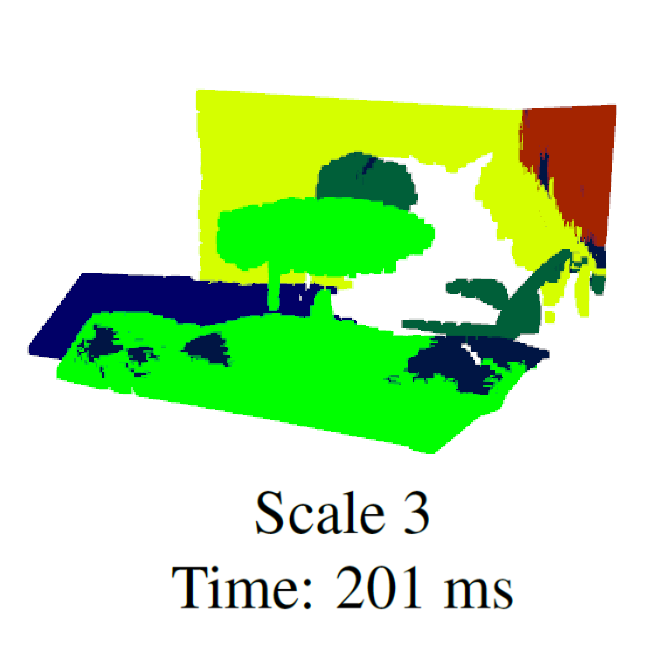
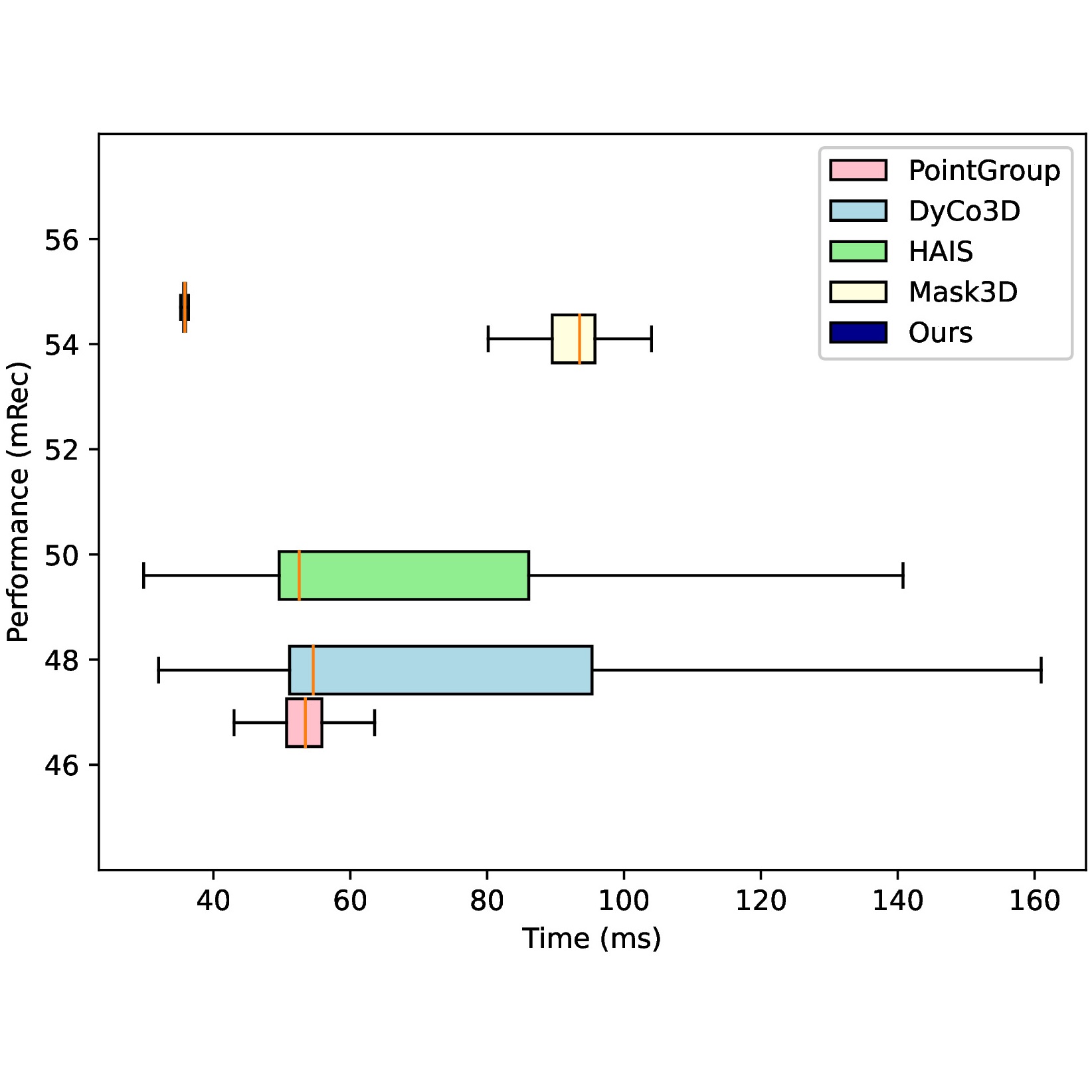
RESSCAL3D++: Joint Acquisition and Semantic Segmentation of 3D Point Clouds
Remco Royen, Kostas Pataridis, Ward van der Tempel, Adrian Munteanu IEEE International Conference on Image Processing (ICIP), 2024 [ArXiv] [Paper] [Code] [Dataset] A significant improvement in performance over RESSCAL3D: resolution scalable 3D semantic segmentation + a new dataset VX-S3DIS exhibiting resolution scalable point streams with semantic labels. |
|
Joint prototype and coefficient prediction for 3d instance segmentation
Remco Royen, Leon Denis, Adrian Munteanu IET Electronics Letters, 2024 [ArXiv] [Paper] [Code] A 3D instance segmentation method which simultaneously learns coefficients and prototypes. The obtained prototypes are visualizable and interpretable. |
|
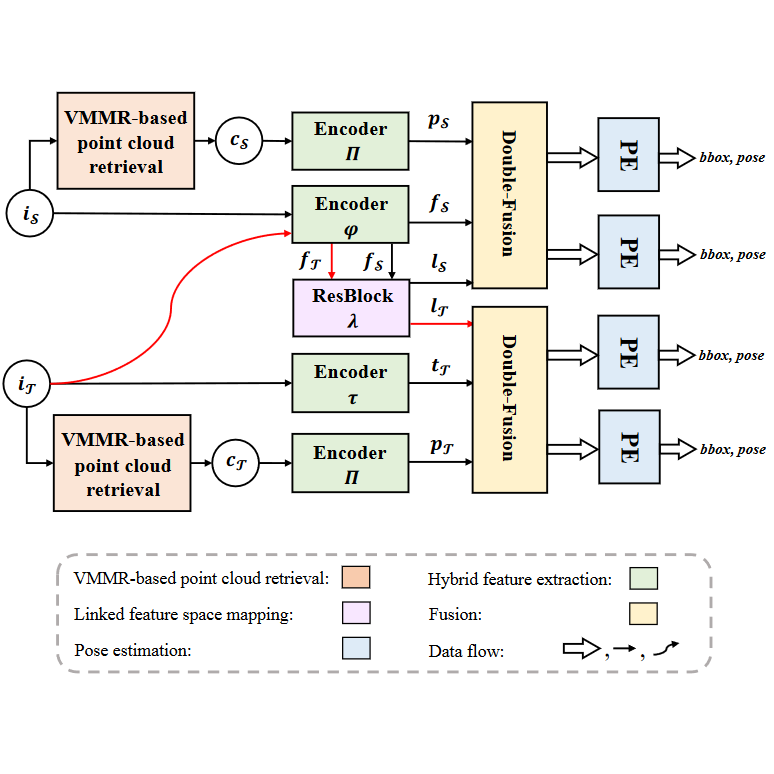
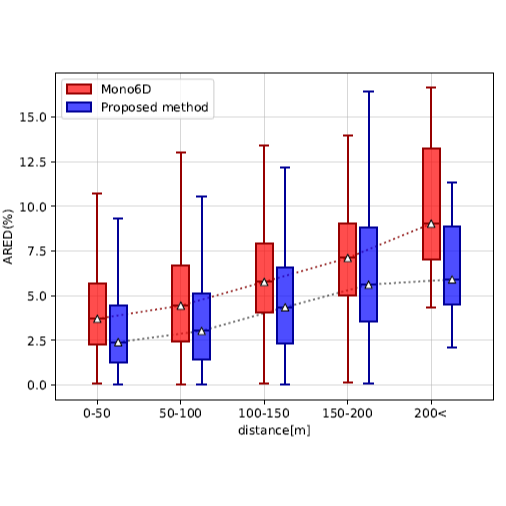
W6dnet: Weakly-supervised domain adaptation for monocular vehicle 6d pose estimation with 3d priors and synthetic data
Yangxintong Lyu, Remco Royen, Adrian Munteanu IEEE Transactions on Instrumentation and Measurement, 2024 [Paper] [Code] 1) The presentation of a new highly realistic synthetic traffic dataset, SynthV6D, for 6D pose estimation. 2) A weakly-supervised domain adaptation approach for 6D pose estimation of vehicles. |
|
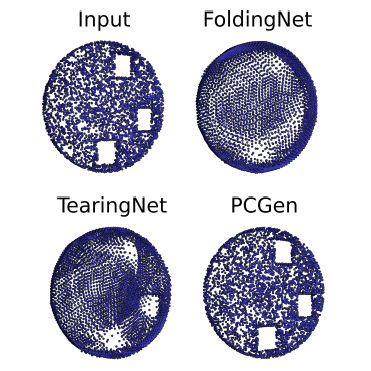
Pcgen: a fully parallelizable point cloud generative model
Nicolas Vercheval, Remco Royen, Adrian Munteanu, Aleksandra Pizurica, MDPI Sensors, 2024 [ResearchGate] [Paper] [Code] A fully parallelizable vector-quantized variational autoencoder model (VQVAE) that generates high-quality point clouds in milliseconds. |
|
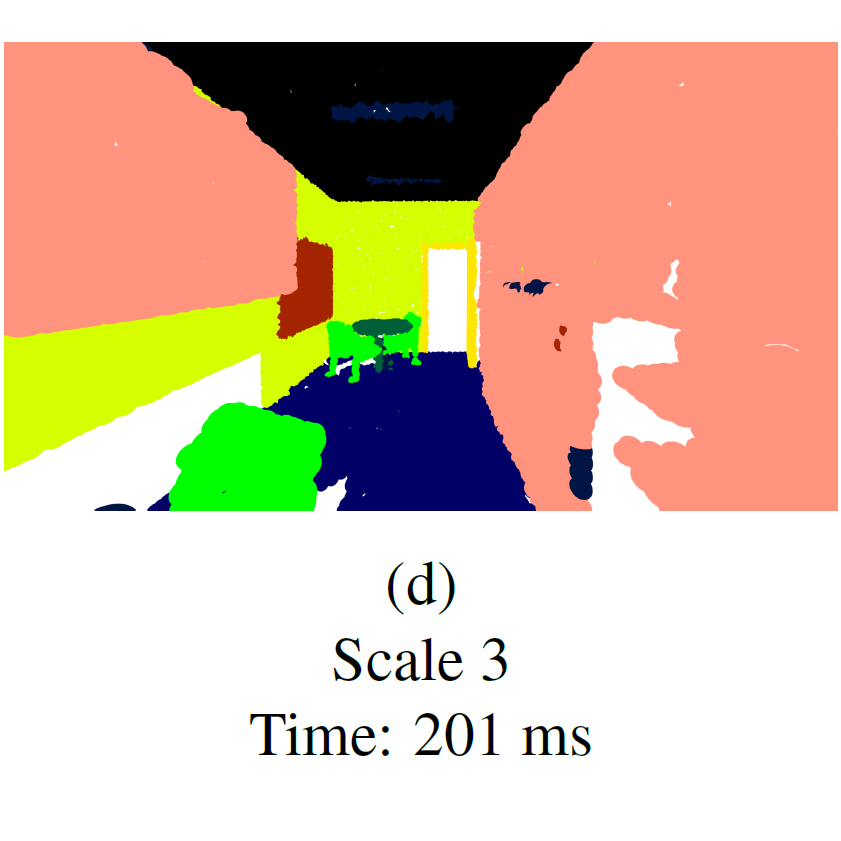
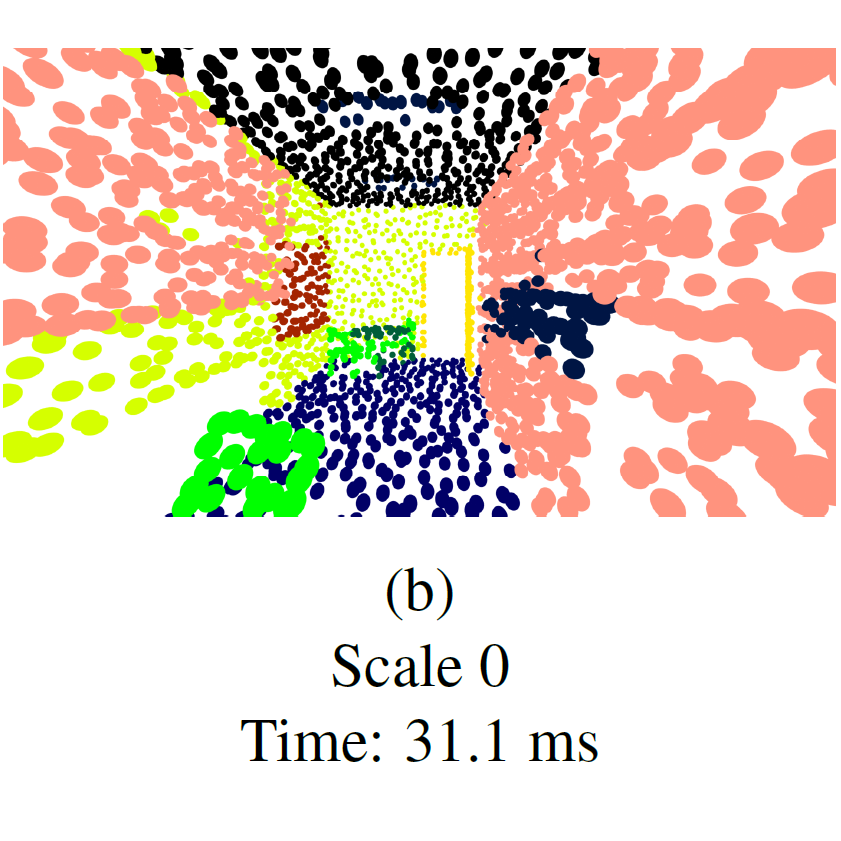
RESSCAL3D: Resolution Scalable 3D Semantic Segmentation of Point Clouds
Remco Royen, Adrian Munteanu IEEE International Conference on Image Processing (ICIP), 2023 [ArXiv] [Paper] Resolution-scalable 3D semantic segmentation of point clouds. By enabling the processing of different resolution scales in parallel, RESSCAL3D is 31-62% faster than the non-scalable baseline and allows early predictions. |
 
|
GPU Rasterization-Based 3D LiDAR Simulation for Deep Learning
Leon Denis, Remco Royen, Nicolas Vercheval, Aleksandra Pizurica, Adrian Munteanu MDPI Sensors, 2023 [ResearchGate] [Paper] A GPU-accelerated simulator that enables the generation of high-quality, perfectly labelled data for any Time-of-Flight sensor, including LiDAR. |
|
Mono6D++: Learning Point Cloud Visibility for 3D Prior-based Vehicle 6D Pose Estimation
Yangxintong Lyu, Olivier Ducastel, Remco Royen, Adrian Munteanu European Workshop on Visual Information Processing (EUVIP), 2023 [Paper] An improvement over Mono6D by the introduction of point cloud visibility prediction. |
|
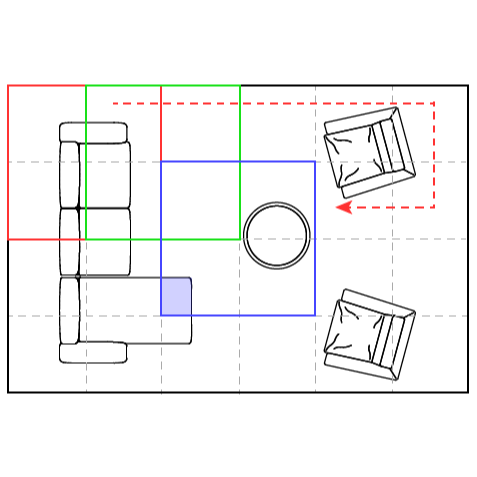
Improved Block Merging for 3D Point Cloud Instance Segmentation
Leon Denis, Remco Royen, Adrian Munteanu International Conference on Digital Signal Processing (DSP), 2023 [ArXiv] [Paper] [Code] A new block merging algorithm suitable for any block-based 3D instance segmentation technique. It significantly and consistently improves the obtained accuracy for all evaluation metrics employed in literature, regardless of the underlying network architecture. |
|
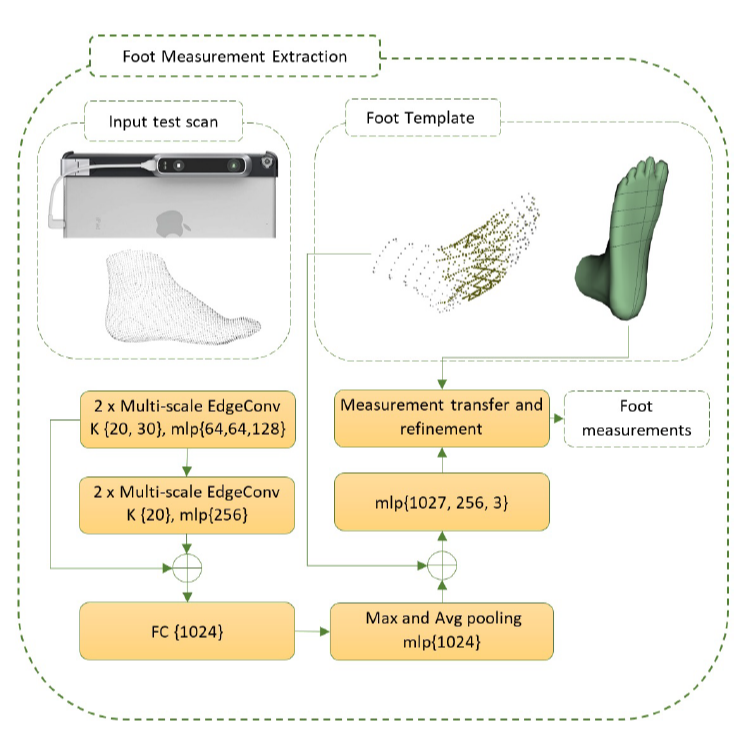
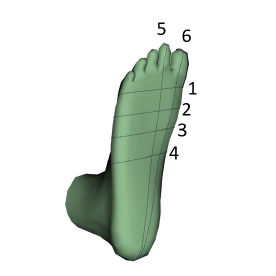
A Deep-learning-based Approach to Automatically Measuring Foots from a 3D scan
Nastaran Nourbakhsh Kaashki, Remco Royen, Xinxin Dai, Pengpeng Hu, Adrian Munteanu IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), 2022 [ResearchGate] [Paper] The first deep-learning-based approach to automatic foot measurement extraction from a single 3D scan. |
|
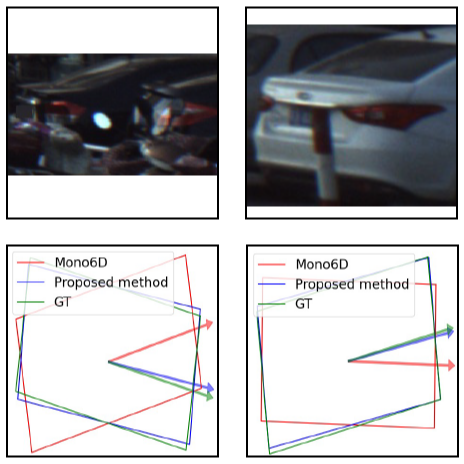
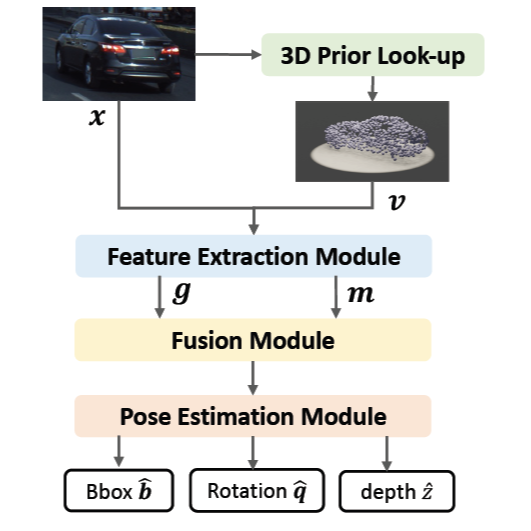
MONO6D: Monocular Vehicle 6D Pose Estimation with 3D Priors
Yangxintong Lyu, Remco Royen, Adrian Munteanu IEEE International Conference on Image Processing (ICIP), 2022 [Paper] A monocular approach for vehicle pose estimation using vehicle 3D priors provided by vehicle make-and-model recognition methods to estimate the 6D pose. |
|
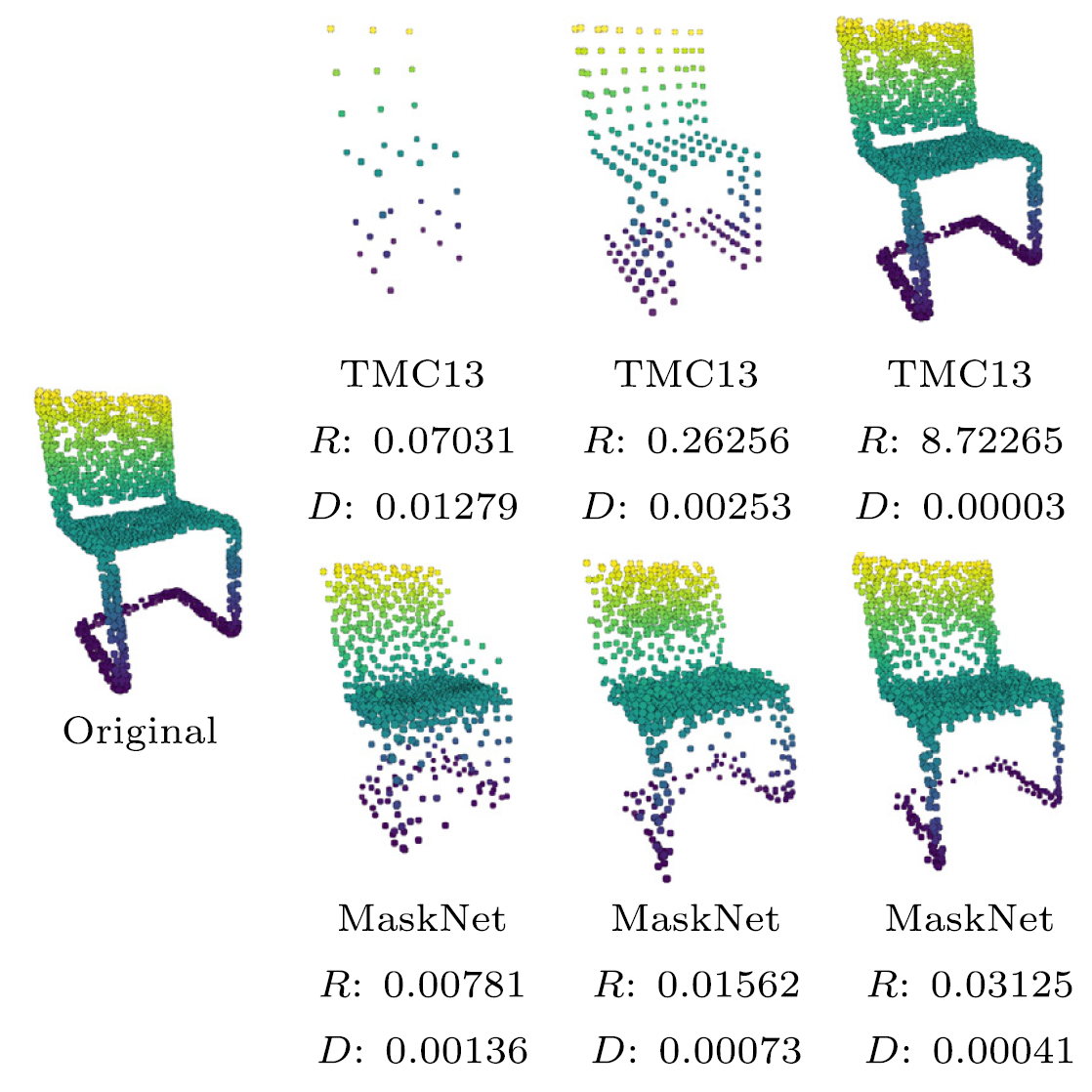
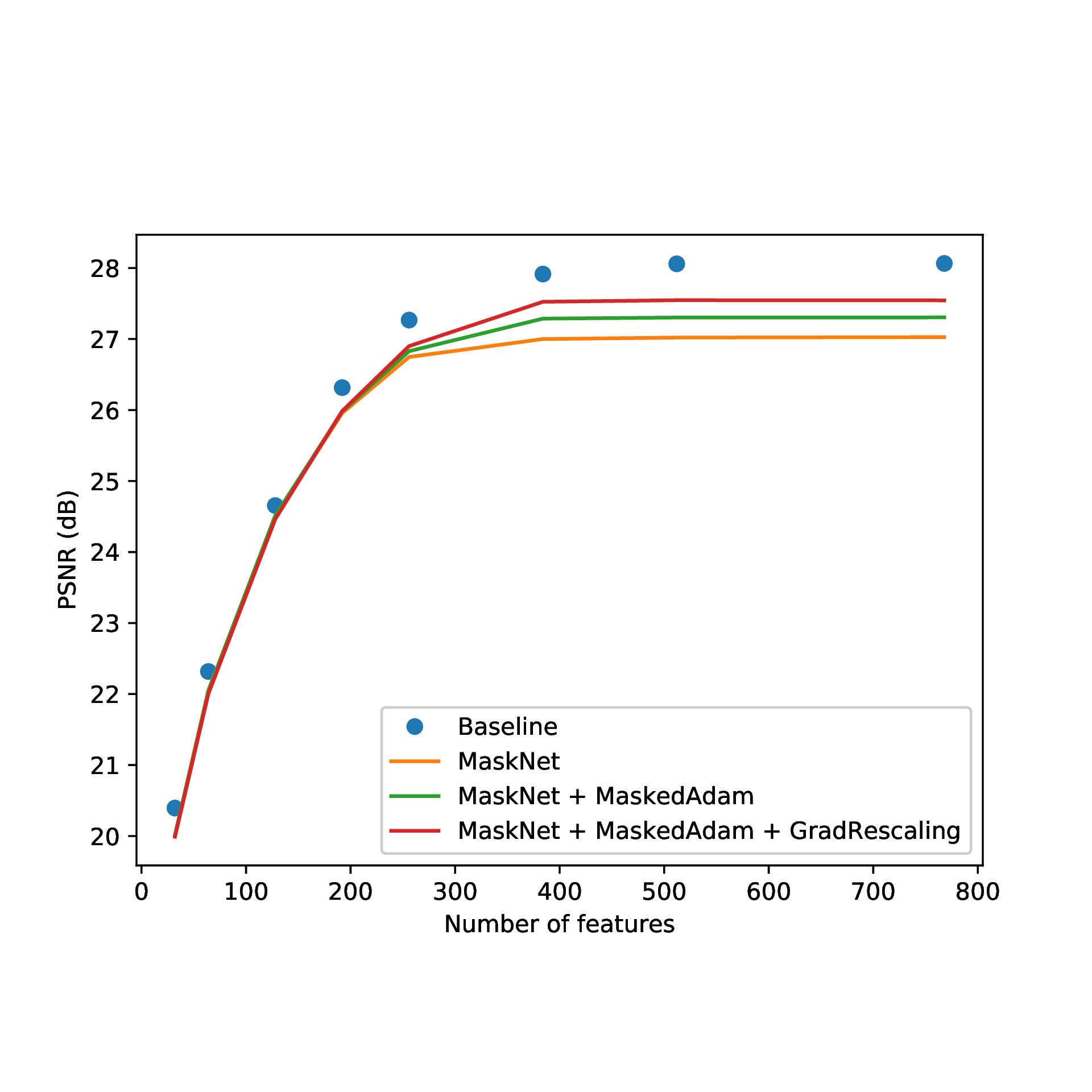
MaskLayer: Enabling scalable deep learning solutions by training embedded feature sets
Remco Royen, Leon Denis, Quentin Bolsee, Pengpeng Hu, Adrian Munteanu Neural Networks (IF 9.7), 2021 [ResearchGate] [Paper] [Code] A new neural network layer. It can be integrated in any feedforward network, allowing quality scalability by design by creating embedded feature sets. |
Additional academic activities |
|
Conference reviewer
CVPR, BMVC, ICIP, DSP, ACIVS |
|
Journal reviewer
Transactions in Image Processing (TIP), Neural Networks |
|
Teaching experiences
Teaching assistant:
Master thesis supervision:
|
|
Created based on Jon Barron's code and Rui Wang's website. Last update: 22 March 2026 |